AI读不懂文档结构?计算所重构Agentic RAG文档推理能力
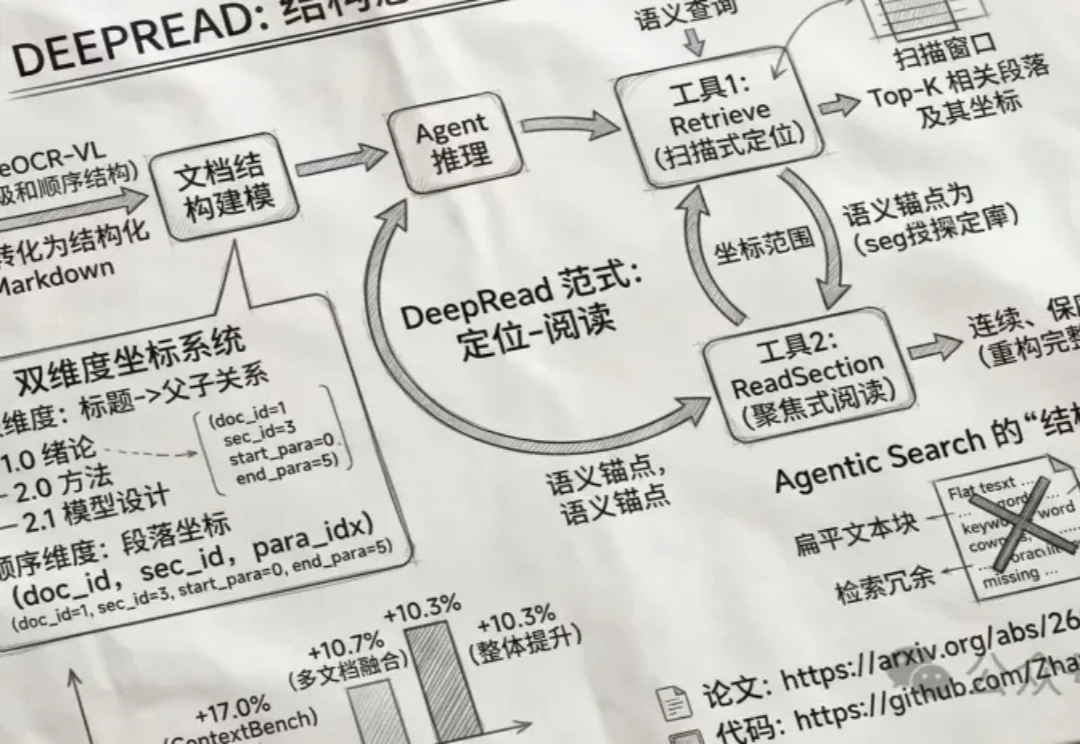
AI读不懂文档结构?计算所重构Agentic RAG文档推理能力DeepRead让AI像人一样阅读文档:利用OCR识别章节结构,先精准定位相关段落,再完整读取上下文,避免碎片化检索。实验显示,其长文档问答准确率提升17%,能自动跳过冗余信息,精准提取财报、论文等复杂内容,无需额外知识图谱,轻量高效。
来自主题: AI资讯
8675 点击 2026-03-16 14:26
 搜索
搜索
DeepRead让AI像人一样阅读文档:利用OCR识别章节结构,先精准定位相关段落,再完整读取上下文,避免碎片化检索。实验显示,其长文档问答准确率提升17%,能自动跳过冗余信息,精准提取财报、论文等复杂内容,无需额外知识图谱,轻量高效。

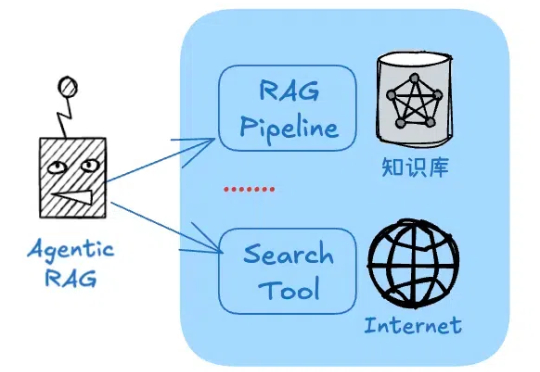
当前,Agentic RAG(Retrieval-Augmented Generation)正逐步成为大型语言模型访问外部知识的关键路径。但在真实实践中,搜索智能体的强化学习训练并未展现出预期的稳定优势。一方面,部分方法优化的目标与真实下游需求存在偏离,另一方面,搜索器与生成器间的耦合也影响了泛化与部署效率。
技术上,从传统的关键词检索,到RAG,大家已经不满足于只是生成对应的简单回答。而是期待大语言模型能够更好地应用于企业级场景,产生更大的价值。不久前,OpenAI推出了最新的深度内容生成神器“DeepResearch”,用户只需一个"特斯拉的合理市值是多少"的提问,
RAG是一种基于“检索结果”做推理的应用,这大大限制了类似DeepSeek-R1模型的发挥空间。但又的确存在将RAG的准确性与DeepSeek深度思考能力结合的场景,而不仅仅是回答事实性问题。比如:

检索-增强生成 (RAG) 是一个永不过时的话题,并在不断扩展以增强LLMs 的功能。对于那些不太熟悉RAG 的人来说:这种方法利用外部知识来增强模型的能力,从外部资源中检索您实际需要的信息。